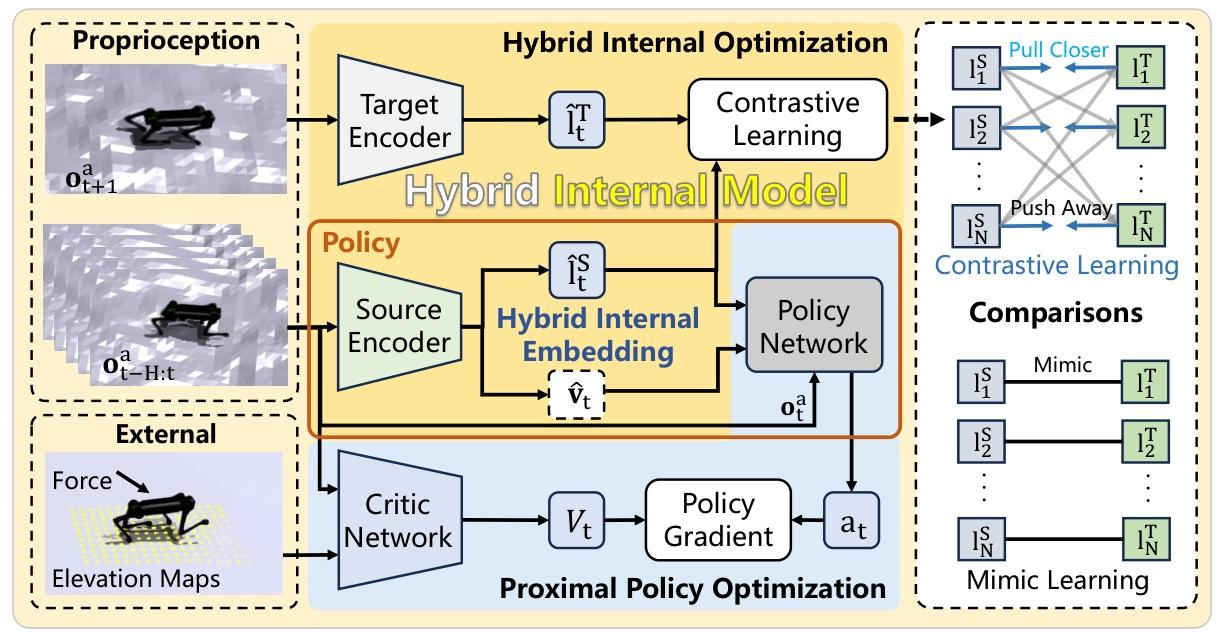
如何写伪代码(以AMP训练算法为例)

如何写伪代码(以AMP训练算法为例)
坷如何写伪代码(以AMP训练算法为例)
伪代码(Pseudocode)是论文中描述算法的核心手段。好的伪代码应当简洁、清晰、无歧义,让读者能快速理解算法的整体流程,而不被具体语言的语法细节干扰。
一、伪代码的基本结构
一篇规范的伪代码通常包含以下部分:
| 部分 | 说明 |
|---|---|
| 标题 | 算法名称,如 ALGORITHM 1: Training with AMP |
| 输入 | 算法所需的输入数据或参数 |
| 输出 | 算法返回的结果(可选) |
| 主体 | 算法的核心逻辑流程 |
二、书写规范
2.1 变量命名
- 使用数学符号而非编程变量名:用 $s$ 而非
state,用 $\pi$ 而非policy - 下标表示时间步或索引:$s_t$ 表示第 $t$ 步的状态,$\tau_i$ 表示第 $i$ 条轨迹
- 希腊字母用于特殊变量:$\pi$(策略)、$\tau$(轨迹)、$\Phi$(特征函数)
2.2 控制流语句
常用的控制流关键字:
- 循环:
for ... do ... end for、while ... do ... end while - 条件:
if ... then ... else ... end if - 赋值:用 $\leftarrow$ 表示,如 $x \leftarrow 0$
- 函数调用:直接写出函数名和参数,如 $collect_trajectory(\pi)$
2.3 缩进与层次
使用缩进表达嵌套关系,一般每一级缩进 4 个空格或 1 个 Tab:
1 | for i = 1, ..., m do |
2.4 注释与说明
在关键步骤后用自然语言补充说明,用 ← 或直接跟在语句后面:
$$\tau_i \leftarrow {(s_t, a_t, r_t^G)_{t=0}^{T-1}, s_T^G, g} \quad \text{collect trajectory with } \pi$$
三、实例:AMP 训练算法
以下以 Adversarial Motion Priors (AMP) 的训练算法为例,展示一篇完整伪代码的写法。
3.1 算法背景
AMP 是一种基于对抗学习的运动模仿方法。其核心组件包括:
- 判别器 $D$:区分参考运动与智能体生成的运动,提供风格奖励
- 策略 $\pi$:在目标任务奖励和风格奖励的联合指导下学习
- 价值函数 $V$:估计状态价值,辅助策略优化
3.2 完整伪代码
1 | Input: M : dataset of reference motions |
3.3 写法解析
(1)输入输出
输入只写算法依赖的外部数据($M$),初始化过程放在输入之后、主循环之前。这符合大多数论文的惯例。
(2)外层循环:数据收集
1 | for trajectory i = 1, ..., m do |
- 用 $\tau_i$ 表示一条完整轨迹,包含状态-动作-奖励序列、终止状态和目标
- 注释
collect trajectory with π说明了数据来源
(3)内层循环:奖励计算
1 | for time step t = 0, ..., T-1 do |
- $d_t$ 是判别器对相邻状态对的判别输出
- 风格奖励 $r_t^S$ 由 $d_t$ 通过公式计算得到
- 最终奖励是目标任务奖励与风格奖励的加权和
(4)判别器更新
1 | b_M ← sample batch from M |
- 从参考数据和经验回放中分别采样
- 用两个 batch 对抗训练判别器
(5)策略与价值函数更新
1 | update V and π using trajectories {τ_i} |
- 使用收集到的轨迹数据同时更新价值函数和策略
四、常见问题与建议
4.1 伪代码的粒度
伪代码应处于自然语言和代码之间的抽象层次:
| 层次 | 示例 | 适用场景 |
|---|---|---|
| 太粗 | “训练模型直到收敛” | 缺少细节,无法复现 |
| 适中 | “$D \leftarrow$ initialize discriminator” | 清晰且不过度具体 |
| 太细 | “$D \leftarrow$ MLP(256, 256, ReLU)” | 过度实现细节,应放在正文 |
4.2 常见符号约定
| 符号 | 含义 | 示例 |
|---|---|---|
| $\leftarrow$ | 赋值 | $x \leftarrow 0$ |
| $\leftarrow$ | 采样 | $x \leftarrow \mathcal{N}(0, 1)$ |
| $\in$ | 属于 | $s \in \mathcal{S}$ |
| $\forall$ | 对所有 | $\forall t \in [0, T]$ |
| $\propto$ | 正比于 | $p \propto \exp(r)$ |
4.3 排版建议
- 算法整体放在一个
algorithm浮动体中,便于交叉引用 - 变量首次出现时在正文中定义,伪代码中直接使用
- 复杂公式(如奖励函数)在正文中推导,伪代码中只引用公式编号
- 控制流关键字(for, while, if)加粗,提高可读性

喜欢这篇文章的人也看了